The Death of Code Reviews (As We Know Them)
AI made writing code cheap. Review is where the time goes now.
AI made writing code cheap. It didn’t make trusting it cheap.
The more code I see AI generate, the less convinced I am that our current approach to code reviews can scale.
For years, code review has been a fairly stable process. Someone spends a few hours or a few days building something, opens a pull request, another engineer reads through the diff, understands what changed, and decides whether it’s ready to merge. It isn’t perfect, but it’s worked because writing the code took a meaningful amount of time. Reviewing it felt proportional.
I see that relationship changing.
A couple of years ago, a pull request containing 800 lines of code usually represented a significant amount of engineering effort. Today, I can ask Cursor to implement a feature, refactor a few files, write tests, and even explain its own reasoning before I’ve finished my coffee. Whether the code is correct is another question entirely, but generating it is no longer the expensive part. Trusting it is.
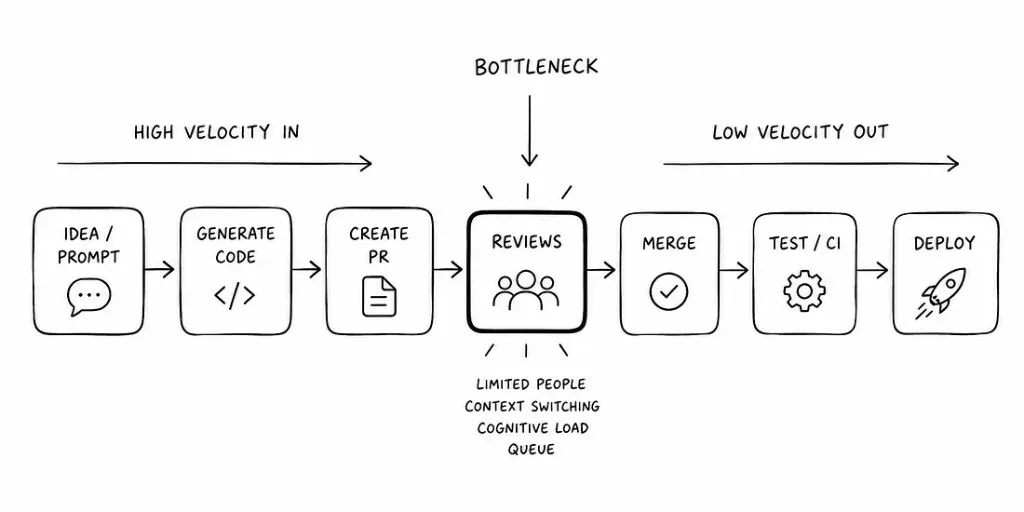
More code, same number of reviewers.
Reviews haven’t caught up
Our review process hasn’t really changed though. We still open a diff and work backwards, scan hundreds of lines of additions and deletions, slowly build a mental model of what the author was trying to achieve, and then decide whether we’re comfortable pressing Merge. I’m not sure that’s the best use of an experienced engineer’s time.
The engineers I respect aren’t valuable because they can read code faster than everyone else. They’re valuable because they ask awkward questions.
- Why was this approach chosen?
- What happens when this dependency fails?
- Are we introducing another pattern we’ll have to support forever?
- Is there a simpler way of doing this?
They’re reviewing the decisions behind the code far more than the syntax itself. That made me wonder if we’ve accidentally made the implementation the centre of the review process when it should really be supporting evidence.
Start with intent, not implementation
Imagine opening a pull request and seeing this first:
This change introduces one new endpoint. Authentication is unchanged. No new dependencies have been added. One database query has changed. Test coverage is unchanged. Service A now depends on Service B. No measurable performance impact is expected.
Engineers already write summaries like this. The problem is they feel optional, and the diff is still treated as the source of truth. I’d almost reverse that: read the summary first, challenge the claims, decide where the risk is likely to be, and only then dive into the implementation to verify those claims instead of using the code to discover them in the first place.
That changes the review from “what happened?” to “do I believe this is the right change?” That’s the more interesting problem.
What I actually want from a review
As code generation gets cheaper, confidence gets harder to earn. I don’t just want to know that something compiles or that the tests passed. I want to know it solves the right problem, doesn’t create three new ones, and isn’t quietly making the system harder to evolve six months from now.
I suspect the next useful tools won’t generate code faster. They’ll make it easier to trust what’s already there. The teams that move fastest won’t ship the most code. They’ll ship changes they can actually stand behind.
That’s the shift I’m interested in: not replacing code reviews, but changing what we spend our time reviewing.
Related
- Ascendproject