Stop Giving AI More Context. Give It Better Examples.
I varied how much code an LLM could see. Token count barely changed. What changed was whether it copied or invented.
Everyone says the fix for bad AI code is simple: give it more context.
I tried that.
The results weren’t what I expected.
We’ve spent decades optimising memory, CPU, disk, and bandwidth. Context is the new bottleneck.
Every extra token costs money, increases latency, consumes context window, and gives the model more opportunities to wander.
The default advice whenever Cursor or Claude gets something wrong is simple:
“Attach more files.”
It sounds sensible. But is it actually true?
I wanted to measure it instead of arguing about it.
The experiment
I built a small React e-commerce application with authentication, products and a shopping basket.
Then I asked Claude Opus 4.8 exactly the same engineering task four times:
Add a wishlist feature allowing users to save products for later.
The only thing I changed was what context was available to Composer: which files I attached, and how much architectural metadata I included.
| Strategy | Context |
|---|---|
| Full Repository | All 19 source files |
| Relevant Feature | Product-related feature folder |
| Relevant Files | Only the files I’d expect an engineer to copy from |
| Minimum Viable Context | Architectural metadata only |
I expected fewer attached files to mean a smaller prompt. It didn’t.
The results
Each run was scored by Composer 2.5 against the full-repo response as ground truth.
| Strategy | Input tokens | Quality | Inventions | Outcome |
|---|---|---|---|---|
| Full Repository | 84,235 | High | None | Complete implementation |
| Relevant Feature | 74,087 | — | — | Architecture only |
| Relevant Files | 113,962 | High | Minor | Nearly identical to full repo |
| Minimum Viable Context | 93,027 | Medium | Significant | Right structure, wrong details |
Look at the token counts. Minimum Viable Context, the strategy with the least attached code, consumed more input tokens than the full repository. Relevant Files, with only a handful of source files, used the most of all.
I wasn’t measuring prompt size. I was measuring agent behaviour. Composer spent the saved budget exploring the workspace, producing longer reasoning, and generating more output. The amount of context I attached turned out to be only part of the prompt the model actually consumed.
The full repository copied; it didn’t invent
The full repository produced the cleanest implementation, invented the least, and required the least manual editing. Rather than reasoning from first principles, the model found similar code, adapted it, and filled in the gaps.
That’s the difference between the full repository and Minimum Viable Context. Both understood the architecture. Both knew the wishlist should mirror the shopping basket. But only one had the shopping basket implementation sitting in front of it.
Imagine asking two junior developers the same task:
“Here’s our architecture. Build a wishlist.”
versus
“Here’s our architecture, plus here’s how the cart works.”
The second developer copies. The first invents.
The missing ingredient wasn’t the architecture. It was examples to imitate. MVC didn’t fail because the prompt was small. It failed because there was nothing to copy from.
Where it did get close, the failures were telling: wrong imports, wrong component APIs, invented hook behaviour, small assumptions that stopped the project compiling. Not wild hallucinations. Wrong details that add up when you’re guessing instead of adapting.
The feature folder wrote a design doc
This was the strangest result. Instead of implementing the feature, Claude produced an architecture write-up. It understood the problem perfectly. It just never wrote the code.
This wasn’t just “not enough context”. It sounds almost like the model thought: I understand this well enough to explain it, but not well enough to safely implement it.
There’s a gap between enough context to understand a task and enough context to confidently implement it. The feature-folder strategy landed in that gap. It had enough to reason about the architecture. It didn’t have enough examples to copy from. So it wrote a plan instead of code. What a cautious engineer does when they’re unsure.
More context didn’t make answers steadily better
It changed how the model solved the problem.
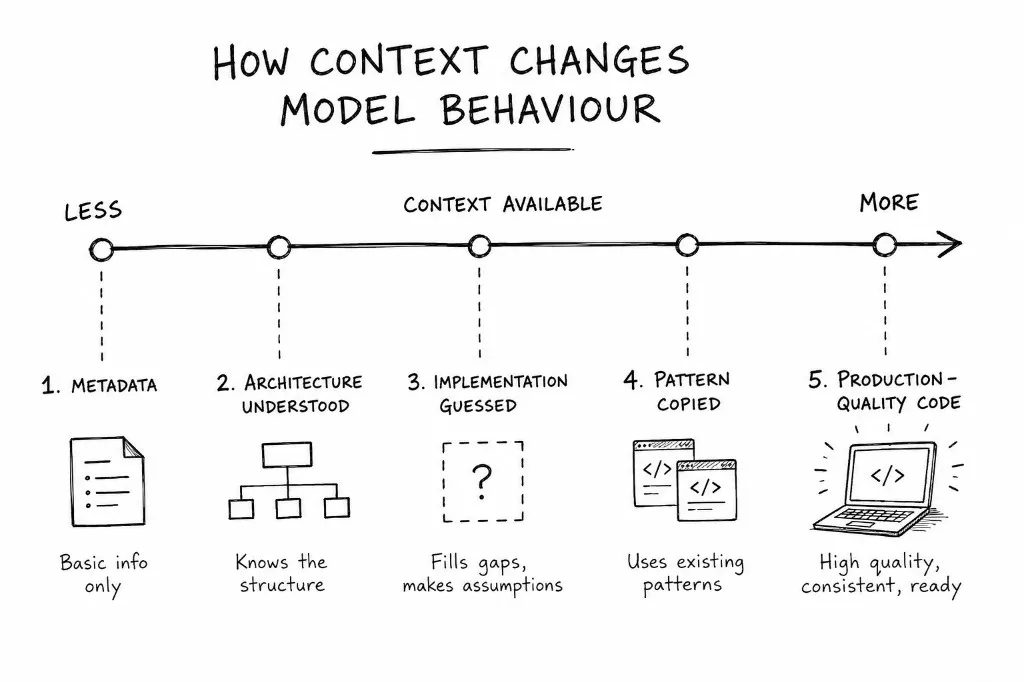
More context didn’t linearly improve quality. It changed the strategy.
On this task the full repository won. The point isn’t “attach everything”. Each strategy pushed the model into a different mode: guessing, explaining, or copying. The optimisation problem isn’t reducing tokens. It’s giving the model just enough code that it stops inventing and starts copying.
One caveat
This was one repository, one feature, and one model. Wishlist-from-cart is almost an ideal pattern-matching task. Cross-cutting refactors, debugging, and performance work may behave very differently.
I’m not convinced bigger context windows are the real race. The interesting problem is giving models the right context.
What I actually learned
The experiment changed my mind.
I expected context to behave like bandwidth: the less you send, the better. Instead, it behaved more like onboarding a new engineer. A little context helps. The right examples help far more. Too little, and the model starts filling in the blanks itself.
For implementation tasks, the best context isn’t the smallest prompt. It’s the smallest amount of information that keeps the model copying your patterns instead of inventing its own.